Introduction
Database normalization is a method in relational database design which helps properly organize data tables. The process aims to create a system that faithfully represents information and relationships without data loss or redundancy.
This article explains database normalization and how to normalize a database through a hands-on example.

What is Database Normalization?
Database normalization is a technique for creating database tables with suitable columns and keys by decomposing a large table into smaller logical units. The process also considers the demands of the environment in which the database resides.
Normalization is an iterative process. Commonly, normalizing a database occurs through a series of tests. Each subsequent step decomposes tables into more manageable information, making the overall database logical and easier to work with.
Why is Database Normalization Important?
Normalization helps a database designer optimally distribute attributes into tables. The technique eliminates the following:
- Attributes with multiple values.
- Doubled or repeated attributes.
- Non-descriptive attributes.
- Attributes with redundant information.
- Attributes created from other features.
Although total database normalization is not necessary, it provides a well-functioning information environment. The method systematically ensures:
- A database structure suitable for generalized queries.
- Minimized data redundancy, increasing memory efficiency on a database server.
- Maximized data integrity through the reduced insert, update, and delete anomalies.
Database normalization transforms overall database consistency, providing an efficient environment.
Database Redundancies and Anomalies
When altering an entity in a table with redundancies, you must modify all repeated instances of information, and any other information related to the changed data. Othrewise, the database becomes inconsistent and anomalies happen when making changes.
For example, in the following unnormalized table:

The table contains data redundancy, which in turn causes three anomalies when making data changes:
1. Insert anomaly. When trying to insert a new employee in the finance sector, you must also know the manager's name. Otherwise, you cannot insert data into the table.
2. Update anomaly. If an employee switches sectors, the manager's name ends up being incorrect. For example, if Jacob changes to finance, Adam stays as his manager.
3. Delete anomaly. If Joshua decides to leave the company, deleting the row also removes the information that a finance sector exists.
The solution to these anomalies is in database normalization concepts and steps.
Database Normalization Concepts
The elementary concepts used in database normalization are:
- Keys. Column attributes that identify a database record uniquely.
- Functional Dependencies. Constraints between two attributes in a relation.
- Normal Forms. Steps to accomplish a certain quality of a database.
Database Normal Forms
Normalizing a database is achieved through a set of rules known as normal forms. The central concept is to help a database designer achieve the desired quality of a relational database.
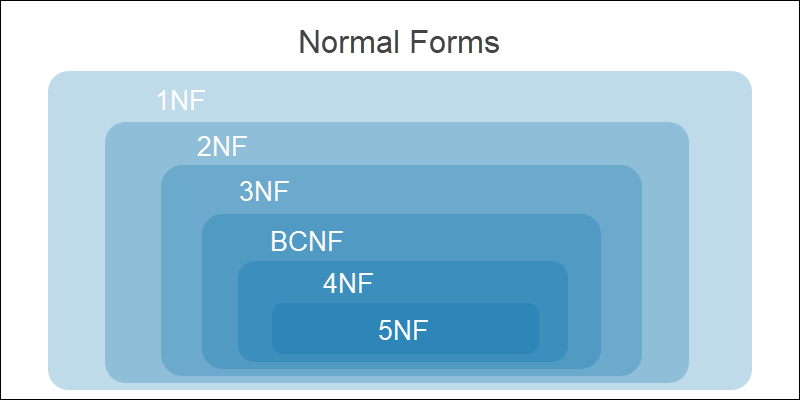
All levels of normalization are cumulative. Previous normal form requirements must be satisfied before moving on to the following form.
The stages of normalization are:
| Stage | Redundancy Anomalies Addressed |
|---|---|
| Unnormalized Form (UNF) | The state before any normalization. Redundant and complex values are present. |
| First Normal Form (1NF) | Repeating and complex values split up, making all instances atomic. |
| Second Normal Form (2NF) | Partial dependencies decompose to new tables. All rows functionally depend on the primary key. |
| Third Normal Form (3NF) | Transitive dependencies decompose to new tables. Non-key attributes depend on the primary key. |
| Boyce-Codd Normal Form (BCNF) | Transitive and partial functional dependencies for all candidate keys decompose to new tables. |
| Fourth Normal Form (4NF) | Removal of multivalued dependencies. |
| Fifth Normal Form (5NF) | Removal of JOIN dependencies. |
A database is normalized when it fulfills the third normal form. Further steps in normalization make the database design complicated and could compromise the functionality of the system.
What is a KEY?
A database key is an attribute or a group of features that uniquely describes an entity in a table. The types of keys used in normalization are:
- Super Key. A set of features that uniquely define each record in a table.
- Candidate Key. Keys selected from the set of super keys where the number of fields is minimal.
- Primary Key. The most appropriate choice from the set of candidate keys serves as the table's primary key.
- Foreign Key. The primary key of another table.
- Composite Key. Two or more attributes together form a unique key but are not keys individually.
As tables decompose into multiple simpler tables, keys define a point of reference for a database entity.
For example, in the following database structure:

Some examples of super keys in the table are:
- employeeID
- (employeeID, name)
All super keys can serve as a unique identifier for each row. On the other hand, the employee's name or age are not unique identifiers because two people could have the same name or age.
The candidate keys come from the set of super keys where the number of fields is minimal. The choice comes down to two options:
- employeeID
Both options contain a minimal number of fields, making them optimal candidate keys. The most logical choice for the primary key is the employeeID because an employee's email can change. The primary key in the table is easy to reference as a foreign key in another table.
Functional Database Dependencies
A functional database dependency represents a relationship between two attributes in a database table. Some types of functional dependencies are:
- Trivial Functional Dependency. A dependency between an attribute and a group of features where the original element is in the group.
- Non-Trivial Functional Dependency. A dependency between an attribute and a group where the feature is not in the group.
- Transitive Dependency. A functional dependency between three attributes where the second depends on the first and the third depends on the second. Due to transitivity, the third attribute is dependent on the first.
- Multivalued Dependency. A dependency where multiple values depend on one attribute.
Functional dependencies are an essential step in database normalization. In the long run, the dependencies help determine the overall quality of a database.
Database Normalization Example - How to Normalize a Database?
The general steps in database normalization work for every database. The specific steps of dividing the table as well as whether to go past 3NF depend on the use case.
Example Unnormalized Database
An unnormalized table has multiple values within a single field, as well as redundant information in the worst case.
For example:
| managerID | managerName | area | employeeID | employeeName | sectorID | sectorName |
|---|---|---|---|---|---|---|
| 1 | Adam A. | East | 1 2 | David D. Eugene E. | 4 3 | Finance IT |
| 2 | Betty B. | West | 3 4 5 | George G. Henry H. Ingrid I. | 2 1 4 | Security Administration Finance |
| 3 | Carl C. | North | 6 7 | James J. Katy K. | 1 4 | Administration Finance |
Inserting, updating, and removing data is a complex task. Performing any alterations to the existing table has a high risk of losing information.
Step 1: First Normal Form 1NF
To rework the database table into the 1NF, values within a single field must be atomic. All complex entities in the table divide into new rows or columns.
The information in the columns managerID, managerName, and area repeat for each employee to ensure no loss of information.
| managerID | managerName | area | employeeID | employeeName | sectorID | sectorName |
|---|---|---|---|---|---|---|
| 1 | Adam A. | East | 1 | David D. | 4 | Finance |
| 1 | Adam A. | East | 2 | Eugene E. | 3 | IT |
| 2 | Betty B. | West | 3 | George G. | 2 | Security |
| 2 | Betty B. | West | 4 | Henry H. | 1 | Administration |
| 2 | Betty B. | West | 5 | Ingrid I. | 4 | Finance |
| 3 | Carl C. | North | 6 | James J. | 1 | Administration |
| 3 | Carl C. | North | 7 | Katy K. | 4 | Finance |
The reworked table satisfies the first normal form.
Step 2: Second Normal Form 2NF
The second normal form in database normalization states that each row in the database table must depend on the primary key.
The table splits into two tables to satisfy the normal form:
- Manager (managerID, managerName, area)
| managerID | managerName | area |
|---|---|---|
| 1 | Adam A. | East |
| 2 | Betty B. | West |
| 3 | Carl C. | North |
- Employee (employeeID, employeeName, managerID, sectorID, sectorName)
| employeeID | employeeName | managerID | sectorID | sectorName |
|---|---|---|---|---|
| 1 | David D. | 1 | 4 | Finance |
| 2 | Eugene E. | 1 | 3 | IT |
| 3 | George G. | 2 | 2 | Security |
| 4 | Henry H. | 2 | 1 | Administration |
| 5 | Ingrid I. | 2 | 4 | Finance |
| 6 | James J. | 3 | 1 | Administration |
| 7 | Katy K. | 3 | 4 | Finance |
The resulting database in the second normal form is currently two tables with no partial dependencies.
Step 3: Third Normal Form 3NF
The third normal form decomposes any transitive functional dependencies. Currently, the table Employee has a transitive dependency which decomposes into two new tables:
- Employee (employeeID, employeeName, managerID, sectorID)
| employeeID | employeeName | managerID | sectorID |
|---|---|---|---|
| 1 | David D. | 1 | 4 |
| 2 | Eugene E. | 1 | 3 |
| 3 | George G. | 2 | 2 |
| 4 | Henry H. | 2 | 1 |
| 5 | Ingrid I. | 2 | 4 |
| 6 | James J. | 3 | 1 |
| 7 | Katy K. | 3 | 4 |
- Sector (sectorID, sectorName)
| sectorID | sectorName |
|---|---|
| 1 | Administration |
| 2 | Security |
| 3 | IT |
| 4 | Finance |
The database is currently in third normal form with three relations in total. The final structure is:
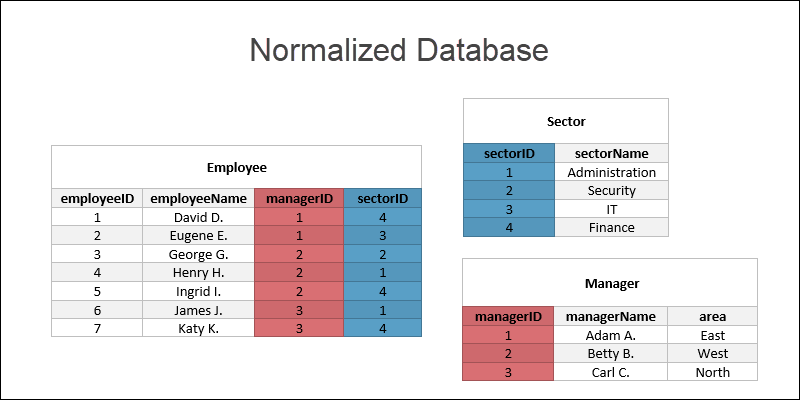
At this point, the database is normalized. Any further normalization steps depend on the use case of the data.
Conclusion
The article showed that database normalization is a method in which a database reduces the amount of redundant information. In the long run, the process helps minimize data loss as well as improve the overall organization.
Database denormalization is a technique used to improve data access performances. Learn more about what database denormalization is and the different techniques used to speed up a database.
If a database is hard to normalize, consider migrating the database to another database type.
