Introduction
Data structures are the backbone of all programmable systems that handle the problem of data storage. All programs deal with the issue of data storage, especially when working with large volumes of data.
Therefore, knowing about data structures and the different available types helps create efficient and functional programs.
This guide introduces the concept of various data structure types and their use cases in programming.

What are Data Structures?
Data structures organize data in a program and represent different data types in physical form.
Every data structure defines:
- The method of connecting a group of elements and their in-memory representation.
- The allowed set of operations and algorithms over the grouped elements.
All operations fall into one of the two following categories:
- Queries, which return information about a data structure without making changes.
- Modifiers, which change the contents of a data structure.
What are Data Structures Used for?
Data structures provide an efficient way to store and access large amounts of data. Various fields of applied programming, such as AI, databases, and others, research the problem of efficient data storage.
Data structures, together with algorithms, are the core of any program. Well-organized data structures help design structured algorithms and reduce time and memory complexity.
Classification of Data Structures
Different data structures provide various ways to store and access data. Each data structure type is suitable for a particular kind of problem.
Depending on the in-memory representation, data structures divide into two categories:
1. Linear data structures are arranged on a single level sequentially (linearly). The data structure is easy to implement and traverse because it imitates computer memory arrangement. Linear data structures branch further into two subcategories based on memory allocation changes:
- Static data structures have a fixed size. Elements can change order, but the memory allocation for the data structure stays the same. An example static data structure is an array.
- Dynamic data structures have a modular size. Runtime changes allow altering the data structure size. Examples of dynamic data structures include queues, stacks, and lists.
2. Non-linear data structures are arranged on multiple levels non-sequentially. The data structure focuses on efficient memory use but is harder to implement and traverse. Examples of non-linear data structures include various types of trees and graphs.
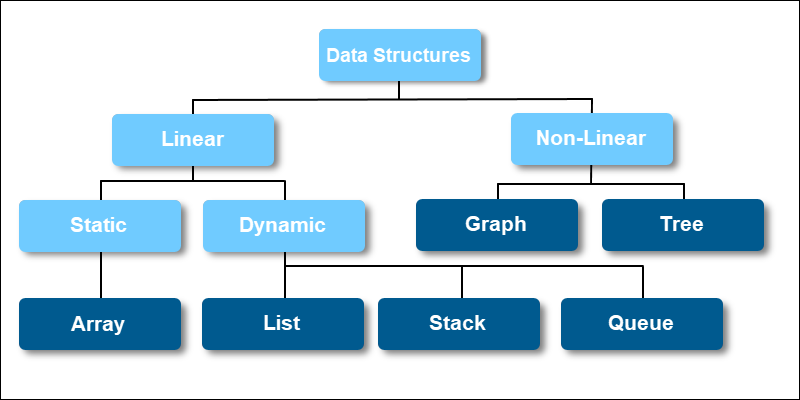
Types of Data Structures
Each data structure type provides unique features. Knowing the difference between primary data structure types helps choose the right solution for a given problem.
Below is a brief overview of the basic types of data structures with examples and use cases.
Array
An array (or vector, tuple, table) is a data structure consisting of a sequence of elements of the same type. It is one of the most basic ways to structure data in programming, which is why arrays appear in most programming languages.
The sequential ordering of data reflects in numbering an array's elements from first to last. The ordinal number is known as an index.
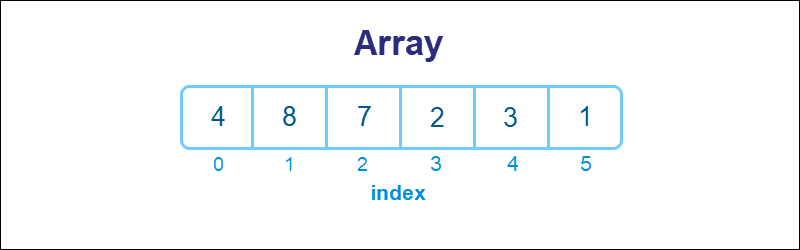
An array has a name, which denotes all elements in the sequence. To access individual members, use the array name and the element's index.
The two main features of arrays are:
- Array elements must be of the same type, regardless of complexity. This feature allows the existence of multi-dimensional arrays (an array whose elements are arrays).
- The length of an array is known in advance and cannot change.
Due to these two features, representing an array in memory is a simple sequential allocation. The total memory an array takes up is the length of an array multiplied by an individual element's size.

The time required to access any element from the array is constant. Algorithms for reading or writing elements are unit instructions based on the following:
- The address of the first component.
- The index.
- The size of an element.
Arrays allow efficient indexing and random access, which is why they often appear in programming.
Avoid using arrays when:
- Elements are of different types.
- The total size of an array is unknown.
- Accessing central data happens often.
Note: Avoid creating arrays based on a maximum size because this method is not memory-friendly. Inserting or removing elements pushes all other elements in the array to the left or right is inefficient.
List
A list, or linked list, is a data structure consisting of a sequence of elements of the same type. Unlike arrays, data in a list connects through indicators.
Most modern programming languages implement lists through pointers. Every element contains an object (node) with two fields. The fields consist of the following:
- Data of any data type (a key).
- A pointer to the following node on the list.
An outside pointer helps access the list as a whole and points to the first element in the list.
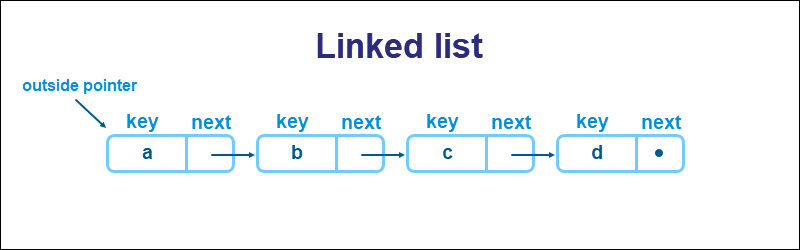
A pointer has the value null to represent the final element in a list or an empty list.
Doubly linked lists feature pointers on both ends of a key. The first pointer points to the previous data, while the second points to the next element.
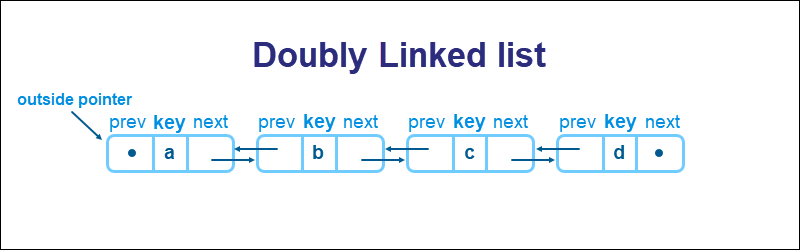
Implementing a pointer on each side enables traversing the list in both directions. Accessing data from a list is done on either side of any given element.
Lists are easy to transform and manipulate using pointers. Inserting or deleting elements requires rerouting pointers instead of moving data.
Use lists when operations such as reordering, insertion, and deletion happen often.
Stack
A stack is a sequence of piled elements, and stacks intuitively function like a stack of trays.
Adding or removing elements occur from the top of the stack, making it a LIFO (Last In, First Out) structure. The last added element is also the first one removed. Adding an element to a stack is called a push, whereas removing is called a pop.
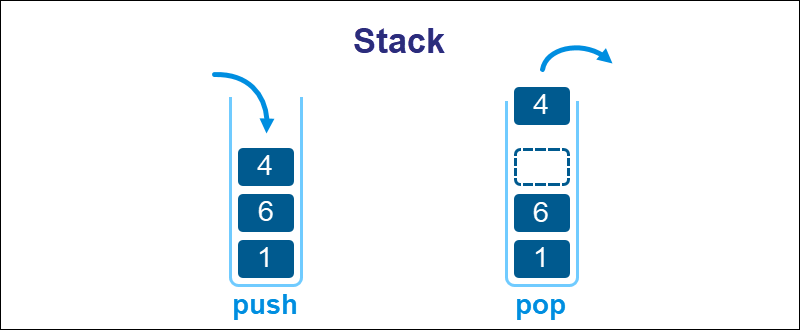
Other data types help implement stacks through specific limitations. For example:
- Stacks as lists. A stack is a type of a list where elements can only be added or removed from the end of the list with push and pop operations.
- Stacks as arrays. A stack easily translates into an array, where the final element takes the highest index value. Tracking the index value allows additional checks for underflow and overflow errors.
Use stacks for any data where the reverse order is essential, such as word reversal, returning to a previous state or step, etc.
Note: Learn how Stack compares to Heap.
Queue
A queue is a type of sequential data structure with lined-up elements. We can compare queues to waiting lines.
Queues are a FIFO (First In, First Out) data structure when it comes to adding and removing elements. Adding and removing elements are called enqueuing and dequeuing, respectively.
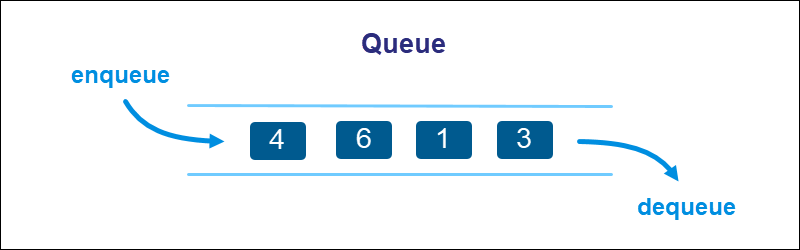
Similar to stacks, queues can be implemented using lists with specific rules. For example, enqueuing elements happens at the end of the list, whereas dequeuing occurs in the front.
Queues help implement job scheduling, resource sharing, and FCFS (First Come, First Serve) systems.
Graph
Graphs are non-linear data structures consisting of vertices (nodes, points) connected by edges (links, lines). A graph aims to represent relationships between individual data points.
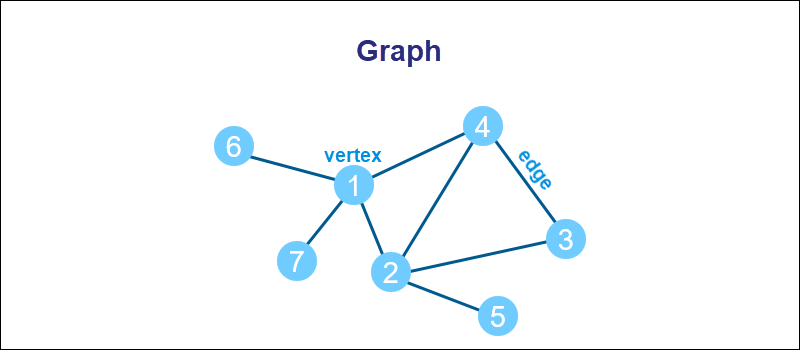
For example, lines connecting different cities (nodes) are a graph. Graphs find many applications in computing problems, such as parallel processing, distributed memory, networking, and graph databases.
There are two methods to represent a graph physically:
1. Adjacency matrix represents a graph through a two-dimensional (2D) array. The total number of vertices determines both dimensions. If the value in the matrix is 1, an edge exists between the two vertices.
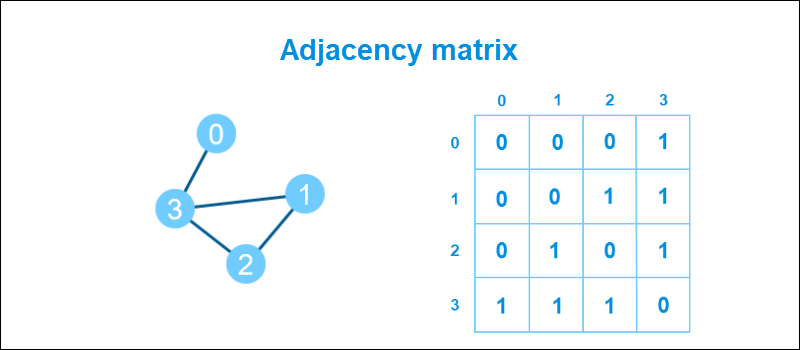
An adjacency matrix is a quick way to check for vertices in a graph.
2. Adjacency list uses an array of linked lists to represent a graph. An index represents every vertex, while the linked list contains all links to the vertex.
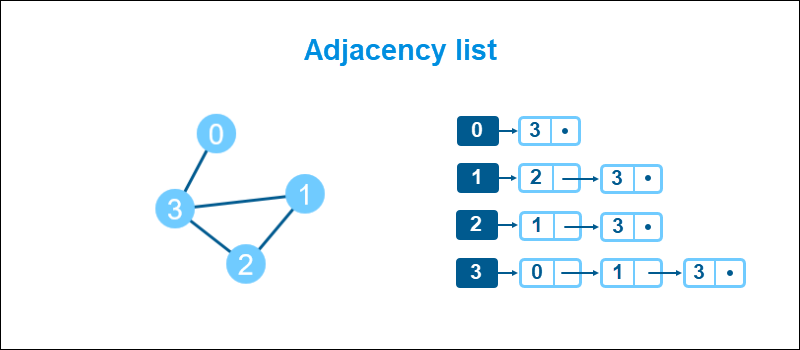
An adjacency list is a memory-efficient way to store graphs with many vertices.
Tree
Trees are non-linear data structures that implement a hierarchical relationship between elements. A table of contents in a book is an example of a tree-like structure.
Similar to a graph, a tree consists of nodes and edges. Each node connects to many children, but every child has exactly one parent. An exception is a topmost node (root), which has no parents, and the bottom nodes (leaves), which have no children.
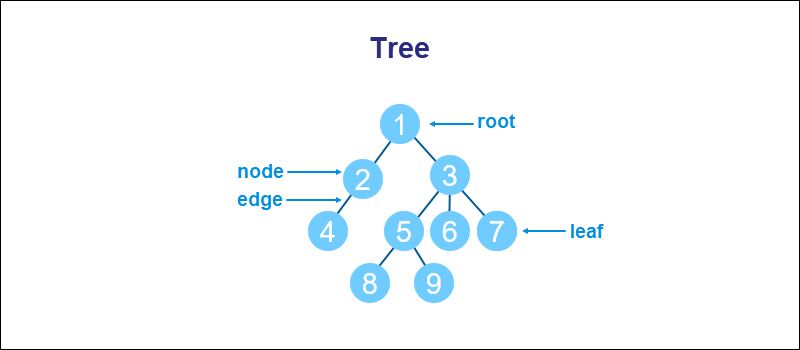
Trees often appear in computing. For example, the folder/directory structure in most operating systems is a tree. The tree data structure also helps define other specialized data structures, such as disjoint sets, priority queues, etc.
Linked lists help represent a general tree with any number of child nodes:
- A null pointer indicates there are no edges connecting to a child node.
- A pointer to a linked list suggests there are child nodes, which we list from left to right.
A typical family of tree-like data structures is binary trees where every node has a maximum of two children (left and right). The added limit simplifies the representation of a binary tree with a doubly linked list.
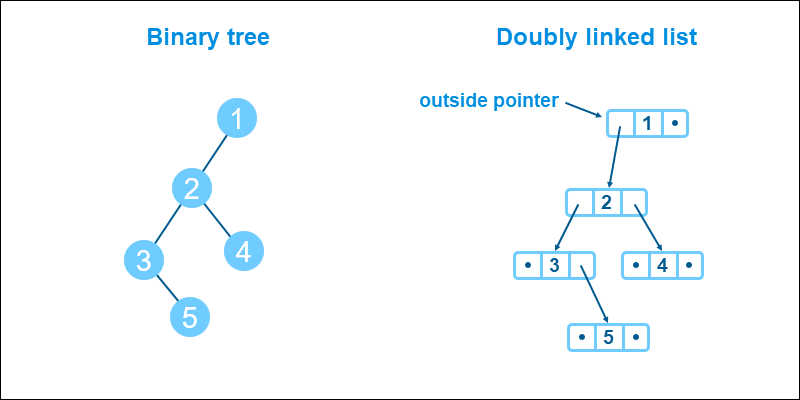
Binary trees help define many other practical data structures, such as binary search trees (BST), heaps, etc.
Conclusion
After reading this guide, you are now familiar with the different data structures and their use in computation. Various data structures help provide multiple efficient ways to represent, store, and manipulate data in a program.
