Availability is among the first things to consider when setting up a mission-critical IT environment, regardless of whether you install a system on-site or at a third-party data center. High availability lowers the chance of unplanned service downtime and all its negative effects (revenue loss, production delays, customer churn, etc.).
This article explains the value of maintaining high availability (HA) for mission-critical systems. Read on to learn what availability is, how to measure it, and what best practices your team should adopt to prevent costly service disruptions.

What Is High Availability?
High availability (HA) is a system's capability to provide services to end users without going down for a specified period of time. High availability minimizes or (ideally) eliminates service downtime regardless of what incident the company runs into (a power outage, hardware failure, unresponsive apps, lost connection with the cloud provider, etc.).
In IT, the term availability has two meanings:
- The period of time a service is available.
- The time the system requires to respond to a request made by a user.
High availability is vital for mission-critical systems that cause lengthy service disruption when they run into a failure. The most effective and common way to boost availability is to add redundancy to the system on every level, which includes:
- Hardware redundancy.
- Software and app redundancy.
- Data redundancy.
If one component goes down (e.g., one of the on-site servers or a cloud-based app that connects the system with an edge server), the entire HA system must remain operational.
Avoiding service interruptions is vital for every organization. On average, a single minute of service downtime costs an enterprise $5,600 (the per-minute figure is in the $450 to $1000 range for SMBs), so it is not surprising companies of all sizes invest heavily into the availability of their IT infrastructure.
While there is overlap between the two terms, availability is not synonymous with uptime. A system may be up and running (uptime) but not available to end users (availability). Availability is also not disaster recovery (DR). Whereas HA aims to reduce or remove service downtime, the main goal of DR is to get a disrupted system back to a pre-failure state in case of an incident.
PhoenixNAP's high-availability solutions enable you to build HA systems and rely on cutting-edge tech that would cost a fortune on an in-house level (global deployments, advanced replication, complete hardware and software redundancy, etc.).
How High Availability Works?
A high availability system works by:
- Having more hardware and software assets than needed so that you have backups capable of taking over if something happens to the primary component.
- Performing regular checks to ensure each component (both primary and the one in reserve) works correctly.
- Creating an automatic failover mechanism that switches operations to a backup component if the primary system goes down.
A HA system requires a well-thought-out design and thorough testing. Planning requires all mission-critical components (hardware, software, data, network infrastructure, etc.) to meet the desired availability standard and have:
- No single point of failure (a component that would cause the whole system to go down if it fails).
- Reliable, ideally automatic failover (switching from the primary component to the backup without losing data or affecting performance).
- Dependable failure detection (so that the system reliably identifies an issue and starts the failover on time).
The more complex a system is, the more difficult it is to ensure high availability. More moving parts mean more points of failure, higher redundancy needs, and more challenging failure detection.
Achieving high availability does not only mean keeping the service available to end users. Even if an app continues to function partially, a customer may deem it unusable based on performance. A poorly performing but still online service is not a highly available system.
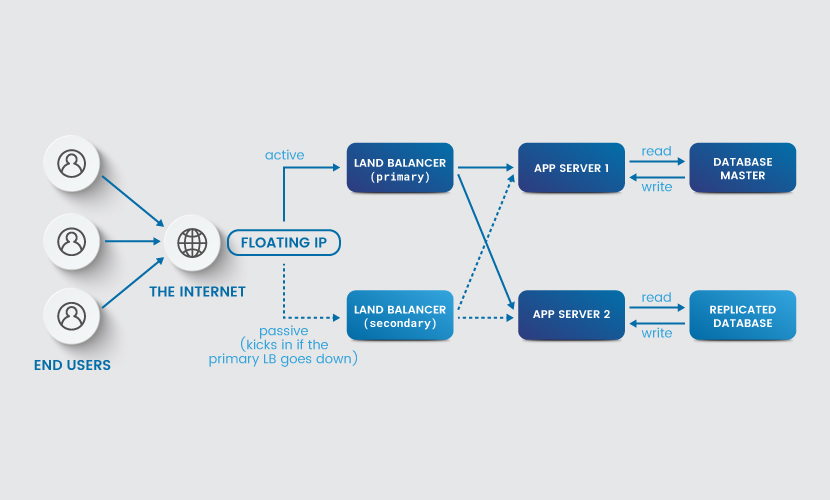
What Are High Availability Clusters?
A high availability cluster is a set of hosts that operate as a single system to provide continuous uptime. Companies use an HA cluster both for load balancing and failover mechanisms (each host has a backup that starts working if the primary one goes down to avoid downtime).
All hosts within the cluster must have access to the same shared storage. Connection to the same database enables virtual machines (VMs) on a given host to fail over to another host in the event of a failure.
A HA cluster can range from two to several dozens of nodes. There is no limit to this number, but going with too many nodes often causes issues with load balancing.
Importance of High Availability
High availability is vital in use cases where a mission-critical system cannot afford downtime. A HA system going down or below a certain operational level severely impacts a business or end user safety. Here are a few examples:
- Autonomous, self-driving vehicles.
- Monitoring devices in healthcare.
- Pressure monitors in oil pipelines.
- Electronic health records (EHRs).
- Hosting equipment in a data center hosting cloud services.
Avoiding downtime is just one of several reasons why high availability is essential. Here are a few others:
- Frequent service disruptions lead to unhappy end users and increase customer churn.
- High availability is a vital indicator of Quality of Service (QoS). Investing in HA means ensuring your brand reputation does not take performance-related hits.
- Minimizing system downtime also reduces the chance of losing critical business data sets.
- Apps with HA tend to have better architectures, which naturally boosts performance and scalability.
Feel like achieving high availability is too big of a task for your in-house team? You might be a prime candidate for outsourced IT - learn all you need to know about offloading computing tasks in our article on managed IT services.
How to Measure High Availability?
The general way to measure availability is to calculate how much time a specific system stays fully operational during a particular period. You express this metric as a percentage and calculate it with the following formula:
Availability = (minutes in a month - minutes of downtime) * 100/minutes in a month
Other metrics used to measure availability are:
- Mean time between failures (MTBF): The expected time between two system failures.
- Mean downtime (MDT): The average time that a system stays nonoperational.
- Recovery time objective (RTO): Also known as estimated time of repair, RTO is the maximum tolerable time a system can stay down after a failure.
- Recovery Point Objective (RPO): The maximum amount of data your company can tolerate losing in an incident.
The most common way to measure HA is with the five-nines availability system in which every level guarantees somewhere between 90% and 99.999% uptime. The table below shows the maximum daily and yearly downtime of every grade:
| Availability level | Maximum downtime per year | Average downtime per day |
|---|---|---|
| One Nine: 90% | 36.5 days | 2.4 hours |
| Two Nines: 99% | 3.65 days | 14 minutes |
| Three Nines: 99.9% | 8.76 hours | 86 seconds |
| Four Nines: 99.99% | 52.6 minutes | 8.6 seconds |
| Five Nines: 99.999% | 5.25 minutes | 0.86 seconds |
The cost increases the higher you go on the "nines" scale. Achieving anything higher than 99% availability in-house requires expensive backups and a dedicated maintenance team. The high price is why most companies that aim for high availability prefer to host at a third-party data center and guarantee the lack of downtime in a Service Level Agreement (SLA).
Note that there is no 100% availability level. No system is entirely failsafe—even a five-nines setup requires a few seconds to a minute to perform failover and switch to a backup component.
How to Achieve High Availability? Eight Best Practices
Below is a list of the best practices your team should implement to ensure high availability of apps and systems. Ideally, you'll apply these tips at the start of your app design, but you'll also be able to use the best practices below on an existing system.

Eliminate Single Points of Failure
Remove single points of failure by achieving redundancy on every system level. A single point of failure is a component in your tech stack that causes service interruption if it goes down.
Every mission-critical part of the infrastructure must have a backup that steps in if something happens to the primary component. There are different levels of redundancy:
- The N+1 model includes the amount of equipment (referred to as "N") needed to keep the system up, plus one independent backup for each mission-critical element. The components are usually active and passive (backups are on standby, waiting to take over when a failure happens) or active and active (the backup is working even when the primary component functions correctly).
- The N+2 model is like N+1, but this strategy ensures the system would withstand the failure of two same components. N+2 is enough to keep most organizations up and running in the "high nines" levels of availability.
- The 2N model contains double the amount of every component necessary to run the system. There's a fully operational mirror backup of the entire setup, like the one you'd prepare for a DR site.
- The 2N+1 model provides the same level of availability and redundancy as 2N with the addition of an extra component for another layer of safety.
Another way to eliminate single points of failure is to rely on geographic redundancy. Distribute your workloads across multiple locations to ensure a local disaster does not take out both primary and backup systems. The easiest (and most cost-effective) way to geographically distribute apps across different countries or even continents is to rely on cloud computing.
Different data centers provide different levels of redundancy. Learn what each facility type offers in our article on data center tiers.
Data Backup and Recovery
A high availability system must have sound data protection and disaster recovery plans. Data backup strategy is an absolute must, and a company must have the ability to recover from storage failures like data loss or corruption quickly.
Using data replication is the best option if your business requires low RTOs and RPOs and cannot afford to lose data. Your backup setup(s) must have access to up-to-date data records to take over smoothly and correctly if something happens to the primary system.
Use PhoenixNAP's backup and restore solutions to create cloud-based backups of valuable data and ensure resistance against cyberattacks, natural disasters, and employee error.
Rely on Automatic Failover
Redundancy and backups alone do not guarantee high availability. You require a mechanism for detecting errors and acting when one of the components crashes or becomes unavailable.
An HA system must almost instantly redirect requests to a backup setup in case of failure. Failover of both the entire system or one of its parts should ideally occur without manual tasks from the admin.
Whenever a component goes down, failover must be seamless and occur in real-time, and the process looks like this:
- The setup has two devices: Machine 1 and its clone Machine 2, usually called Hot Spare.
- Machine 2 continually monitors the status of Machine 1 for any issues or errors.
- The primary Machine 1 fails or shuts down after encountering a problem.
- Machine 2 comes online, and every user request now automatically goes to Machine 2 instead of Machine 1. This process happens without any impact on end users.
- When the admin resolves the root of the problem, Machines 1 and 2 go back to their initial roles.
Early failure detection is vital to improving failover times and ensuring high availability. One of the software solutions we recommend for HA is Carbonite Availability, software suitable both for physical and virtual data centers. For fast and flexible cloud-based infrastructure failover and failback, check out Cloud Replication for Veeam.
Set Up Around-the-Cloud Monitoring
Even the best failover mechanism is not worth much if it does not launch quickly enough. Your HA system requires a tool that provides:
- Around-the-clock monitoring.
- Real-time alerting capabilities.
- Automated remediation that reacts to problems via agent procedures (scripts).
- Remote control and endpoint protection management to troubleshoot issues.
- Support for routine server maintenance and patching.
Our articles on the best server and cloud monitoring tools present a wide selection of solutions worth adding to your tool stack.
Proper Load Balancing
Load balancing is necessary for ensuring high availability when many users access a system at the same time. Load balancing distributes workloads between system resources (e.g., sending data requests to different servers and IT environments within a hybrid cloud architecture).
The load balancer (which is either a hardware device or a software solution) decides which resource is currently most capable of handling network traffic and workloads. Some of the most common load balancing algorithms are:
- Round Robin: This load balancer directs requests to the first server in line. The balancer moves down the list to the last one and then starts from the beginning. This method is easy to implement and widely used, but it does not consider if servers have different hardware configurations.
- Least Connection: In this case, the load balancer selects the server with the least number of active connections. When a request comes in, the load balancer looks for a server with the fewest current connections. This method helps avoid overloading web servers when end user sessions last for a long time.
- Source IP Hash: This algorithm determines which server to select according to the source IP address of the request. The load balancer creates a unique hash key using the source and destination IP address.
While load balancing is essential, the process alone is not enough to guarantee high availability. If a balancer only routes the traffic to decrease the load on a single machine, that does not make the entire system highly available.
Like all other components in a HA infrastructure, the load balancer also requires redundancy to stop it from becoming a single point of failure.
Test HA Systems Frequently
Your team should design a system with HA in mind and test functionality before implementation. Once the system is live, the team must frequently test the failover system to ensure it is ready to take over in case of a failure.
All software-based components and apps also require regular testing, and you must track the system's performance using pre-defined metrics and KPIs. Log any variance from the norm and evaluate changes to determine the necessary changes.
Hight Availability Is a No-Brainer Business Investment
No matter what size and type of business you run, any amount of downtime can be costly. Each hour of service unavailability costs revenue, turns away customers, and risks business data. From that standpoint, the cost of downtime dramatically surpasses the costs of a well-designed IT system, making investments in high availability a no-brainer decision if you've got the right use case.




